Niederländisch verstehen ohne Training – ein Projektbericht aus dem 1. Semester
Wer viele Jahre in der Übersetzungsbranche gearbeitet hat, kennt das Problem nur zu gut: Eine Übersetzung ist selten nur eine sprachliche Aufgabe. Parallel muss die passende Fachterminologie recherchiert werden – und zwar so, dass sie auch tatsächlich dem Sprachgebrauch der jeweiligen Fachcommunity entspricht. Fehlen diese Begriffe, werden Übersetzungen vielleicht noch verständlich, aber sie treffen dann nicht den gewünschten Ton.
Das passiert, weil dann Quellbenennungen schlicht wörtlich übersetzt werden, unabhängig davon, ob die daraus resultierenden Benennungen in der Zielsprache überhaupt gebräuchlich sind. Das kann auch leicht dazu führen, dass die Übersetzung nun doch nicht nur unglücklich, sondern ggf. sogar falsch wird. Genau hier wäre es enorm hilfreich, zumindest eine belastbare Liste üblicher Fachbegriffe zur Verfügung zu haben.
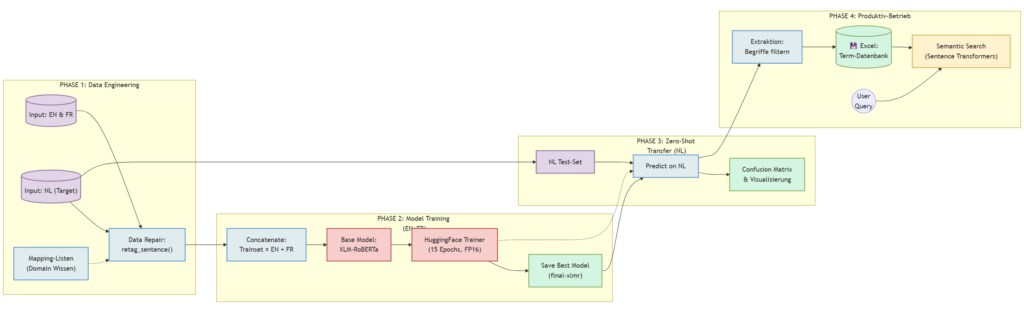
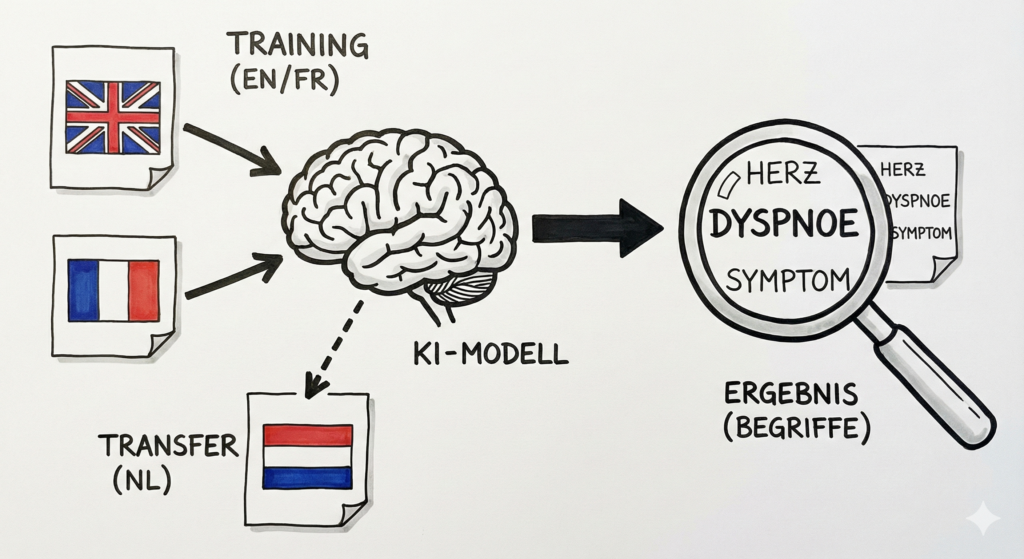
In einem Projekt im ersten Semester des Masterstudiums wurde genau diese Fragestellung untersucht: die Entwicklung einer Künstlichen Intelligenz, die niederländische medizinische Fachbegriffe erkennt, obwohl sie im Training ausschließlich englische und französische Texte gesehen hat. Der zugrunde liegende Ansatz – Zero-Shot Cross-Lingual Transfer – zeigt eindrucksvoll, was mit heutiger Open-Source-Technologie in kurzer Zeit realisierbar ist.
Der „Zoo“ der vorgefertigten Gehirne
Der Begriff „KI“ wird derzeit häufig fast automatisch mit ChatGPT gleichgesetzt. Für Entwicklerinnen und Entwickler existiert jedoch eine breite Landschaft spezialisierter Modelle, etwa über Plattformen wie Hugging Face. Und die Anzahl verfügbarer Modelle steigt fast täglich.

Der entscheidende Vorteil: Das Rad muss nicht immer wieder neu erfunden werden. Für nahezu jeden Anwendungsfall stehen bereits vortrainierte Modelle zur Verfügung, etwa zum
- Zusammenfassen von Texten
- Analysieren von Stimmungen (Sentiment Analysis)
- Umwandeln von Sprache in Text
- Analyse oder die Erstellung von Bildern
- oder zum Verstehen mehrsprachiger Inhalte
Für dieses Projekt fiel die Wahl auf XLM-RoBERTa – ein Modell, das bereits darauf trainiert ist, Texte in rund 100 Sprachen zu verarbeiten. Es ist vergleichbar mit einer breiten Grundausbildung, auf die anschließend eine fachliche Spezialisierung aufsetzt.
Da XLM-RoBERTa seinen Schwerpunkt vor allem auf das Verständnis von Kontext legt, wurde das System um ein weiteres Modell ergänzt. Zum Einsatz kam spaCy, das insbesondere auf die Analyse grammatischer Strukturen und die Zuordnung von Wortarten spezialisiert ist. Durch diese Kombination lassen sich kontextuelle Informationen aus dem Sprachmodell mit explizitem sprachlichem Wissen verbinden. Während XLM-RoBERTa Hinweise darauf liefert, dass ein Begriff fachlich relevant ist, unterstützt spaCy dabei, wie dieser Begriff syntaktisch im Satz eingebettet ist. Die Ergänzung beider Ansätze erhöhte die Stabilität der Erkennung und reduzierte Fehlzuordnungen, insbesondere bei komplexen Satzstrukturen.
Also irgendwie so, als ob man ein Haus baut und für jedes Gewerk die passenden Handwerksbetriebe einsetzt.
Das Experiment: Lernen durch Kontext
Ziel des Projekts war die Extraktion medizinischer Fachbegriffe mit Fokus auf Herzinsuffizienz. Die Besonderheit: Dem Modell wurden zu keinem Zeitpunkt niederländische Fachbegriffe gezeigt.
Die Trainingsdaten bestanden aus englischen Texten mit markierten Fachbegriffen sowie französischen Texten mit entsprechenden Annotationen. Zum Einsatz kam dabei der ACTER-Datensatz, eine frei verfügbare Sammlung fachsprachlicher Texte aus verschiedenen Domänen und Sprachen. Er verdeutlicht, dass nicht nur für KI-Modelle umfangreiche Bibliotheken existieren, sondern ebenso für qualitativ hochwertige Datensätze.
Auch hier muss das Rad nicht neu erfunden werden: Viele Aufgaben lassen sich auf Basis bereits kuratierter, öffentlich zugänglicher Daten realisieren. Die eigentliche Bewährungsprobe erfolgte anschließend mit niederländischen Texten, die im Training nicht enthalten waren.
Warum funktioniert dieser Ansatz?
Das Modell lernt keine klassischen Vokabellisten nach dem Muster „Heart Failure = Herzinsuffizienz“. Stattdessen lernt es Kontexte. Es erkennt Muster in Satzstrukturen und in der Umgebung von Wörtern, die mit hoher Wahrscheinlichkeit auf Krankheiten oder Symptome hinweisen. Da XLM-RoBERTa sprachübergreifende Strukturen erfasst, kann dieses Wissen von einer Sprache auf eine andere übertragen werden.
Vom „Daten-Müll“ zur Suchmaschine
Ein wesentlicher Teil der Arbeit bestand nicht im eigentlichen Modelltraining, sondern in der Datenaufbereitung. Reale Daten sind selten sauber. Entsprechend musste ein sogenannter Repair-Step implementiert werden, um fehlerhafte oder inkonsistente Annotationen zu korrigieren und dem Modell qualitativ hochwertige Trainingsdaten bereitzustellen.
Das Ergebnis war schließlich mehr als eine reine Begriffsextraktion. Die entwickelte Anwendung ermöglicht eine semantische Suche: So kann etwa auf Englisch nach einer Benennung gesucht werden, und das System findet aus den relevanten Stellen in niederländischen Dokumenten die passende niederländische Benennung. Nicht immer perfekt, aber selbst in diesem kleinen Uni-Projekt schon ganz gut.
Ergebnisse
Der Ansatz erwies sich als erfolgreich. Das Modell identifizierte im niederländischen Testdatensatz Fachbegriffe, die in den Trainingsdaten nicht enthalten waren. Es fand also kein bloßes Auswendiglernen statt, sondern eine Übertragung des gelernten Prinzips auf eine neue Sprache.

Ausblick: Warum eigene Modelle statt ChatGPT?
Naheliegend ist die Frage, warum für solche Aufgaben nicht einfach ein großer Chatbot wie ChatGPT eingesetzt wird. Für den professionellen Einsatz sprechen jedoch mehrere Gründe klar für spezialisierte, eigene Modelle:
- Datenschutz: Sensible Daten verlassen nicht das eigene System. Das hier entwickelte Modell kann lokal, etwa auf einem Laptop, betrieben werden.
- Kosten: Kleine, spezialisierte Modelle sind im laufenden Betrieb oft deutlich günstiger als die dauerhafte Nutzung externer APIs.
- Präzision: Durch gezieltes Fine-Tuning auf domänenspezifische Daten übertreffen spezialisierte Modelle häufig generische Alleskönner.
Fazit
Das Projekt zeigt, wie stark die Einstiegshürden für leistungsfähige KI-Systeme gesunken sind. Immer seltener geht es darum, Algorithmen von Grund auf neu zu entwickeln. Die eigentliche Kompetenz liegt heute darin, vorhandene Bausteine sinnvoll zu kombinieren, Datenqualität sicherzustellen und Ergebnisse kritisch einzuordnen.
Auch wenn heute vieles „von der Stange“ verfügbar ist, bleibt die Herausforderung bestehen, zu wissen, was man auswählt, wie sich die einzelnen Komponenten sinnvoll kombinieren lassen und wie sich die Qualität der Ergebnisse bewerten und verbessern lässt. Für das hier vorgestellte Projekt war nahezu alles in irgendeiner Form bereits vorhanden – Modelle, Bibliotheken, Datensätze. Doch diese Bausteine zu einem funktionierenden Gesamtsystem zusammenzuführen, erwies sich als alles andere als trivial. Datenstrukturen passen nicht immer nahtlos zueinander, Trainingsläufe erfordern mitunter mehr Speicher oder leistungsfähigere GPUs, und nicht selten verhält sich der Code anders als erwartet. In solchen Momenten ist die Fähigkeit gefragt, Fehler systematisch zu identifizieren und zu beheben. Vor allem aber braucht es eine klare Vorstellung vom Weg zum Ziel.

Rückblickend sind in das Projekt deutlich mehr als 80 Stunden Arbeit geflossen – wobei ein nicht unerheblicher Teil davon auch schlicht aus Warten bestand, bis ein Trainingsdurchlauf abgeschlossen war.
Und dennoch: Der Weg von „Science Fiction“ zu praxistauglichem Handwerkszeug ist damit endgültig im Alltag angekommen. Und die Entwicklung beschleunigt sich quasi täglich.



{kind=link}